
提升决策,自动化反馈分析,AI 助手 AskViable
AskViable: AI 辅助工具,自动化客户反馈分析,提供实用洞察,改善决策和客户满意度,适合企业高效管理!
LOADING

Ragen-AI项目提出StarPO框架,革命性地通过强化推理训练大型语言模型智能体。该框架利用轨迹级优化解决多轮强化学习中的挑战,有效避免模型崩溃和“回声陷阱”, enabling LLMs to exhibit robust reasoning and decision-making in interactive environments. 探索Ragen-AI,了解如何构建更智能、稳定的AI智能体。
Ragen-AI的核心是StarPO算法,它通过交替进行轨迹生成和优化,强化LLM智能体的推理过程。 项目研究发现并提供了预测训练不稳定的指标,并通过数据过滤等策略提高了训练效率和稳定性。 Ragen-AI是推动AI智能体在复杂任务中实现长期规划和推理的关键技术进展。
使用强化学习方法训练大型语言模型 LLM 智能体。
在交互式、随机环境中部署和训练智能体。
采用独特的StarPO State-Thinking-Action-Reward Policy Optimization 框架。
将智能体与环境的互动过程建模为马尔可夫决策过程 MDP。
执行由轨迹生成 Rollout 和轨迹优化 Update 组成的交替训练流程。
通过优化整个多轮互动轨迹来最大化预期的累积奖励,而非仅优化单步行为。
支持如PPO和GRPO等多种策略优化算法。
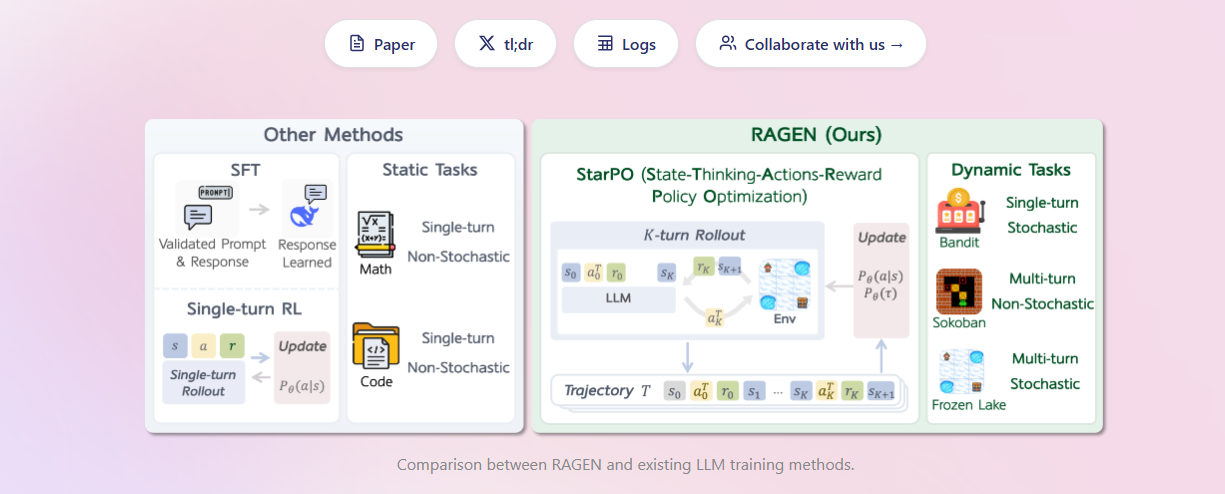
专为多轮智能体RL设计: 有效克服了将单轮RL方法直接应用于多轮智能体训练所带来的不稳定性。
避免“回声陷阱”: 独特的训练策略和轨迹优化方法,防止智能体训练后陷入重复和缺乏推理的模式。
提升训练稳定性: 研究发现并利用关键指标预测模型崩溃,并提出过滤低方差轨迹等方法增强训练稳定性。
促进推理能力涌现: 强调奖励设计对于鼓励智能体生成可解释的中间推理步骤,并维持推理能力的重要性。
轨迹级优化: 通过优化完整的互动轨迹,更好地支持智能体进行长期规划和决策。
高效性: 通过策略性数据过滤可以提高训练效率。
AI研究人员: 致力于提升大型语言模型在复杂、交互式环境中的表现和推理能力。
强化学习研究者: 探索专门针对AI智能体和LLM的新型RL算法和框架。
智能体系统开发者: 构建需要在动态、不确定环境中进行多步决策和规划的AI应用,如高级游戏AI、机器人控制。
涉及多模态交互的研究者: RAGEN的扩展项目VAGEN可用于训练视觉语言模型智能体。
希望解决AI智能体训练中不稳定性问题的实践者。
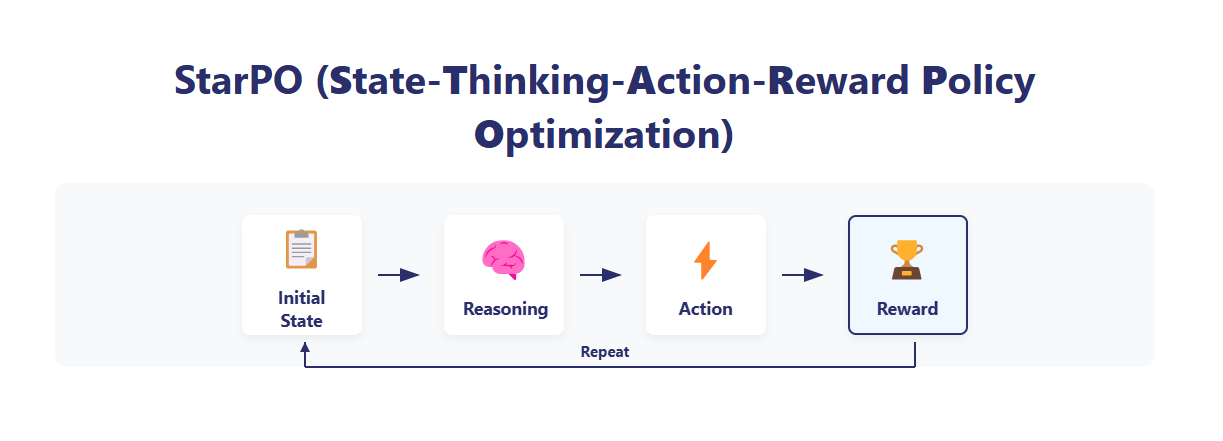
理解Ragen-AI的StarPO框架原理及其MDP建模方法。
准备或定义智能体将要互动的特定交互环境,包括状态表示、动作空间、状态转移函数和奖励机制。
选择一个合适的作为基础的大型语言模型。
根据RAGEN项目的代码或论文实现StarPO算法,设置Rollout和Update阶段的参数。
执行训练过程,让LLM智能体与环境进行多轮互动生成轨迹,并使用这些轨迹优化智能体策略。
在训练过程中,监控奖励标准差、梯度范数等指标,以便及时发现并应对潜在的模型崩溃风险。
根据任务需求精细设计奖励函数,以鼓励智能体表现出期望的推理行为。
参考RAGEN项目公开发布的论文或代码库获取详细的实现指导。
推荐指数: ★★★★☆
打分理由: Ragen-AI项目在训练能在复杂交互环境中进行推理和决策的LLM智能体这一前沿领域取得了重要进展。 其提出的StarPO框架针对多轮强化学习的挑战,特别是模型崩溃和“回声陷阱”问题,提供了创新的解决方案。 对于推动AI智能体研究和发展,以及构建需要强大推理能力的下一代AI应用,Ragen-AI具有显著的研究价值和指导意义。 考虑到它主要是一个研究框架,其易用性和普适性可能不如面向终端用户的产品,因此给出四星推荐。
本站当拿AI导航提供的Ragen-AI:训练AI对话智能体,让交互更智能稳定都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由当拿AI导航实际控制,在2025年4月26日 上午11:23收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,当拿AI导航不承担任何责任。

